da Gilberto Ficara | Set 10, 2009 | Articoli
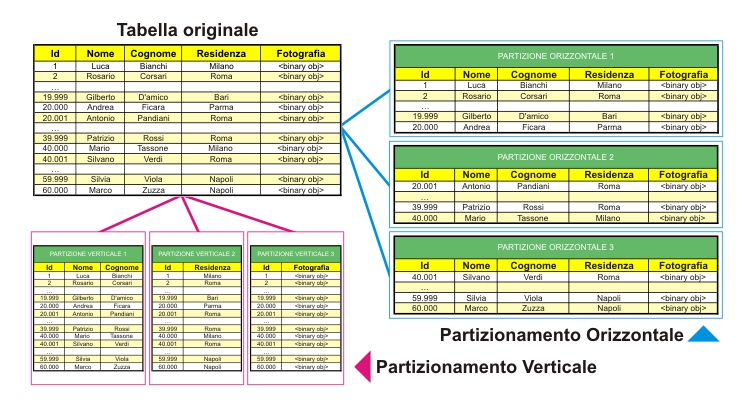
Di Corrado Pandiani, pubblicato su Linux&C. n° 64. Le novità più interessanti della versione 5.1 di MySQL Con il rilascio della versione 5.0 MySQL ha introdotto le funzionalità avanzate che da tempo tanti utilizzatori chiedevano: stored procedure, stored function,...