di Patrizio Tassone – Pubblicato su Linux&C. n° 54.
La replicazione nativa di MySQL
La replicazione nativa di MySQL offre ottime opportunità di scalabilità, come si è potuto intuire nella prima puntata di questo articolo, e non è un caso che portali ad altissimo traffico quali YouTube, Flickr, Wikipedia, Digg, del.icio.us, solo per citare i più noti, utilizzino questa tecnologia per servire migliaia, talvolta milioni di utenti ogni giorno.
In questo articolo cercheremo di indagare più a fondo sugli scenari che si possono avvantaggiare della replicazione, sia in termini di scalabilità che di affidabilità.
Scenari di utilizzo
La replicazione, come si è visto, dispone di un host deputato a raccogliere tutte le connessioni in scrittura da parte dei client, che vengono riversate su un file di log (direttiva log-bin in my.cnf) che poi viene letto dagli altri host slave, riallineando tutte le basi di dati in un paradigma di shared-nothing, che non vede la presenza di costosi dischi condivisi.
L’utilizzo principe di una tecnologia come questa è relativa all’ambito web, in particolare come layer di back-end per la memorizzazione delle informazioni di portali ad alto traffico (contenuti dinamici, utenti, metadati di interesse statistico utili per il datawarehouse con finalità di marketing), dove le operazione di selezione pura (select) sono in un ordine di grandezza superiore rispetto alle scritture effettuate.

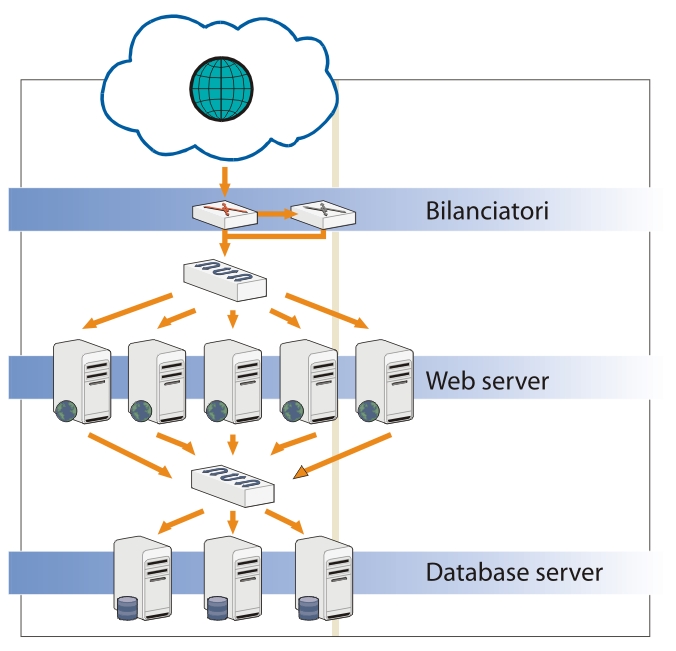
Lo scenario più frequente, e più semplice, è quello visibile in figura 1, che vede la presenza di un bilanciatore, rigorosamente ridondato, che suddivide il traffico in entrata su più web server che costituiscono, in questo caso, il lato applicativo dell’infrastruttura (nel caso più semplice, Apache + PHP/Perl/Python/Ruby o quant’altro); la batteria di server con Apache, in numero variabile a seconda del numero di accessi previsti, della banda in ingresso, della complessità delle operazioni applicative, sono connessi direttamente al back-end di memorizzazione dei dati: un host, il Master, accetterà le scritture mentre gli altri host verranno interrogati nel caso di letture.


Lo scenario è leggermente più complesso nel caso in cui, tra la batteria dei web server e il back-end, si frapponga un layer di application server (figura 2, scenario tipico in ambiti Java), dove risiede parte della logica applicativa: lato database non vi è molta differenza, se non che l’aggiunta di un layer intermedio offre una scalabilità maggiore e un minor numero di connessioni concorrenti.
Per sfruttare appieno le possibilità offerte da questa infrastruttura, le applicazioni devono avere una minima conoscenza dell’architettura che sarà utilizzata in produzione: in verità, le uniche informazioni di cui devono disporre gli sviluppatori sono relative alla presenza di due tipi di connessioni, una in scrittura (verso il master), una in lettura (bilanciata fra più slave).
Non necessariamente i layer superiori devono conoscere il numero esatto di slave presenti nella infrastruttura, in quanto sistemi di virtualizzazione più o meno complessi possono astrarre questa informazione.
Una prima possibilità, forse la più semplice da implementare, almeno nella forma base, vede utilizzo del DNS che, in round robin, bilancia gli accessi tra gli slave, con un file di zona che conterrà qualcosa di simile alle righe seguenti:
master A 192.168.1.100
slave A 192.168.1.110
slave A 192.168.1.120
slave A 192.168.1.130
I client potranno riferire le connessioni a master.retelocale.lan per il master e slave.retelocale.lan per i diversi slave e, a meno di cache-ing degli IP, potranno bilanciare le letture sui diversi database server.
In alternativa, possono essere utilizzati direttamente appliance di bilanciamento, realizzate con hardware dedicati (Cisco, Alteon i più diffusi) o con sistemi software (Linux LVS, Balance e similari), inserendo tutti gli slave dietro a tale device.
In caso di caduta di un nodo slave “nascosto” dal balancer, la configurazione dell’apparato dovrà provvedere ad escludere l’IP del server caduto; nel caso di uso puro di DNS, sarà necessario implementare un servizio di monitoring e far eseguire aggiornamenti dinamici ai record DNS utilizzando nsupdate.
In alternativa, è possibile specificare direttamente all’interno della logica applicativa gli IP dei server database, anche se questo comporta una certa scomodità nel caso in cui venga modificata dinamicamente l’architettura, in particolare in caso di failure.
Caduta del master
La divisione in master e slave fa sorgere immediatamente una prima osservazione, più che lecita: cosa accade se il master ha una failure grave e smette di funzionare?
La notizia positiva, che in questi frangenti fa scorgere un accenno di sorriso al project manager incaricato della supervisione del portale, è che il servizio continua ad essere erogato, e l’impatto sugli utenti è minimo, almeno per quanto riguarda la fruizione dei contenuti.
Se stiamo parlando di una portale di informazione o di un forum ad altissimo traffico, gli utenti potranno ancora leggere gli articoli e i post, effettuare ricerche, ma non potranno inserire commenti – operazione che comporta una scrittura sul master.
MySQL ovviamente dispone dei meccanismi di recover di un simile evento: per avere la certezza (quasi) assoluta di non perdere alcun record, la soluzione consigliata potrebbe essere quella di mettere sotto HA classico il nodo master, e solo questo, utilizzando storage condiviso, eventualmente remotizzato con iSCSI o AoE, che permette una buona affidabilità offrendo, nel contempo, una riduzione dei costi non indifferente.
In alternativa, si può optare per l’elezione di uno degli slave al ruolo (provvisorio) di master, operazione che vedremo tra un attimo in pratica: l’idea è quella di promuovere uno slave al ruolo di master, eventualmente sospendendolo dal ruolo di slave fino a quando il master non sarà completamente reintegrato (non obbligatorio, a seconda del carico un server MySQL può compiere egregiamente entrambe le operazioni).
In genere, quando questa è la policy che viene decisa in fase di progetto, è preferibile identificare uno slave come “candidato master”, di solito il server dotato di maggiori risorse computazionali e un MTBF superiore.
E’ però necessario informare tutti gli slave che l’host dal quale stavano leggendo gli aggiornamenti è cambiato, e che continuino la lettura da un altro nodo.
Sostituzione del master
La caduta del master impedisce l’aggiornamento della base dei dati, e quando il fermo si prolunga oltremodo può essere conveniente utilizzare uno degli slave e promuoverlo a master per accettare le nuove scritture da parte dei client.
La modifica della configurazione deve essere propagata agli altri host della replicazione: ricordate, infatti, che nel file di configurazione my.cnf degli stessi era indicato l’host cui connettersi e dal quale leggere il log-bin? Se questo viene a mancare tutta la configurazione deve essere aggiornata, comprendendo anche un reset dello slave neo-eletto, per essere sicuri che altre informazioni presenti accidentalmente nel log-bin dello stesso non vadano ad alterare la base dei dati in modo improprio. Normalmente la sostituzione del server è provvisoria e, proprio per questo, la configurazione statica, quella presente nel file di configurazione, non verrà modificata.

Lo scenario, a livello di IP, è quello visto la volta scorsa, e riproposta in figura 4: nell’esempio il il .100 cade, il .110 prende il posto del .100 e il .120 si collega al 110 per leggere le query di update.
Per prima cosa sullo slave01 (IP 110) sarà obbligatorio controllare che la direttiva log-bin sia presente nel file di configurazione: per uno server slave tale file di log non è necessario ma ora, diventando master, diventa fondamentale affinché la replicazione diventi possibile.
Nel caso la direttiva log-bin non fosse attiva, dopo l’inserimento della stessa è doveroso un riavvio del server.
Le ulteriori operazioni da compiere, a MySQL ovviamente avviato, sono le seguenti:
mysql-110> reset master;
mysql-110> slave stop;
Con la prima istruzione si effettua un reset del server nella sua veste di master: serve a ripulire i log, nel caso qualche istruzione fosse presente, magari ereditata dalla fase di installazione. Il secondo comando impartito, invece, blocca la replicazione, visto che il polling sull’IP ormai caduto continua senza sosta: questa operazione non è fondamentale, ma lo diventa nel caso in cui si attui l’IP aliasing relativo all’IP del master caduto, per evitare comportamenti anomali.
Sul secondo slave, invece, le operazioni sono diverse: per prima cosa fermiamo la replicazione
mysql-120> slave stop;
Adesso si può effettuare il cambio dei parametri necessari per la nuova connessione: in realtà, poiché gli utenti sono stati già configurati anche sugli slave (all’epoca della creazione facemmo replicare anche l’istruzione GRANT, si veda lo scorso numero), l’unico cambio da effettuare è solo l’IP del master.
mysql-120> CHANGE MASTER TO MASTER_HOST='172.16.2.110';
La sintassi è piuttosto chiara: nel caso in cui venissero cambiati altri parametri, quali username, password, il file di binlog da leggere, oppure il timeout, si dovranno inserire le informazioni da modificare una dopo l’altra nell’istruzione precedente, separate da virgole; dal manuale ufficiale:
mysql> CHANGE MASTER TO
MASTER_HOST='master2.mycompany.com',
MASTER_USER='replication',
MASTER_PASSWORD='bigs3cret',
MASTER_PORT=3306,
MASTER_LOG_FILE='master2-bin.001',
MASTER_LOG_POS=4,
MASTER_CONNECT_RETRY=10;
A questo punto non rimane che far ripartire la replicazione:
mysql-120> slave start;
Interrogando lo stato dello slave, ci possiamo sincerare del fatto che tutto sia in ordine:
mysql-120> SHOW SLAVE STATUS;
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.1.110
Master_User: slave02
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Il Master_Host è cambiato, adesso compaiono le coordinate del vecchio slave, ora diventato Master: una prova semplice di creazione di una nuova tabella, o l’inserimento di un record potrà fugare ogni dubbio circa la funzionalità delle modifiche apportate.
Proviamo a riavviare a far ripartire MySQL sull’host 120, che svolge ancora il compito di slave anche se è cambiato il master al quale connettersi, e a lanciare un nuovo SLAVE STATUS: il server starà ancora replicando ma dall’IP che gli è stato passato con il CHANGE MASTER e non da quello presente nella configurazione!
Questo fatto potrebbe non essere piacevole ai più, anche perché sembrerebbe trovare poche spiegazioni logiche: sarà sufficiente controllare il file master.info presente nella directory di MySQL per capire cosa sia successo:
slave02# cat master.info
[...]
172.16.2.110
slave02
pass02
[...]
master.info riporta tutte le informazioni relative alla replica dal master, che hanno la precedenza rispetto a quelli presenti nel file di configurazione: tale file, a differenza di my.cnf, viene influenzato dai comandi di CHANGE MASTER ed è persistente al riavvio del server.
Nel caso in cui si voglia effettuare un reset completo dello slave è opportuno eseguire
mysql-120> SLAVE STOP; RESET SLAVE; SLAVE START;
perché la configurazione venga riletta da my.cnf.
In questo caso si ottiene quanto segue:
mysql-120> show slave status \G
Slave_IO_State: Connecting to master
Master_Host: 192.168.1.100
Master_User: slave02
Master_Port: 3306
Slave_IO_Running: No
Slave_SQL_Running: Yes
E’ tornato tutto nella norma: poiché il master è ancora fermo, la replicazione si è bloccata, come testimonia il No relativo a Slave_IO_Running.
Aggiornamento dei client
Il problema maggiore nel failure del Master non è elevare a tale ruolo un altro dei database server che, come avete visto, è piuttosto semplice. Certo, ci sono altre considerazioni da fare per un servizio veramente a prova di errore, ma sono considerazioni molto specifiche, una per tutte: chi è lo slave più aggiornato? Essendo asincrona, anche se molto veloce, non necessariamente gli slave sono tutti allo stesso livello.
Il problema maggiore, si diceva, è quello di informare del cambiamento gli application server o la batteria di web server: nel caso analizzato inizialmente di una connessione verso un indirizzo risolto dal DNS, tramite opportuni monitor che valutino lo stato dei servizi attivi è possibile aggiornare dinamicamente il record con nsupdate:
# nsupdate -k chiave.key << EOF
update delete master.retelocale.lan A
update add master.retelocale.lan 300 A 172.16.1.1
send
EOF
Ovviamente il tutto andrà eseguito dopo aver concesso le necessarie autorizzazioni ed aver configurato i permessi affinché questa operazioni possa avvenire in tutta sicurezza. In questo modo i client continueranno a collegarsi a master.retelocale.lan, ma l’indirizzo risolto questa volta sarà diverso.
Anche nel caso degli slave si può effettuare una operazione simile a quella appena vista, facendo attenzione affinché il round robin venga mantenuto integro.
Se invece la connessione avviene tramite IP diretto (oppure hostname presenti in /etc/hosts), che magari è inserito all’interno di file di configurazione delle applicazioni difficilmente modificabili, è opportuno utilizzare sistemi di clustering, quali ad esempio heartbeat, affinché l’IP venga migrato dal master caduto verso lo slave neo-eletto a master, in modo che non si perda l’associazione IP_master->Host_master.
Se questo è lo scenario che viene utilizzato, è consigliabile però decidere a priori qual è l’host candidato all’elezione, in modo da configurare il servizio di HA solo su questo, attivando gli opportuni sistemi di monitoraggio (dalla connessione di rete passando per lo switch, a cavi cross, a cavi seriali null-modem, nel caso la vicinanza delle macchine lo permetta, ecc.), affinché la migrazione avvenga senza particolari problemi.
Ritorno del Master
Già, prima o poi quel server dovrà tornare: a seconda di quanto passa dal fermo, se poche ore o qualche giorno, la base di dati presente sul master potrebbe essere poco aggiornata o estremamente disallineata: la linea generale vuole che il vecchio master entri nella replicazione come uno slave, in modo da leggere gli aggiornamenti dal nuovo master.
Nel caso però sia passato molto tempo, i log potrebbero essere stati ruotati e cancellati, e quindi non vi è più alcuna possibilità di aggiornarsi da essi.
E’ consigliabile ripristinare da un check point ben noto, il più recente possibile: allo scopo, normalmente, è deputato l’ultimo backup che, sincronizzato con la rotazione del log, permette di effettuare un reintegro in tutta sicurezza.
Se neppure questa soluzione è fattibile, a meno di complessi script di sync che agiscono sulla base di dati, c’è da effettuare la copia bruta delle informazioni da un nodo verso il vecchio Master.
Quando l’host rientrato sarà allineato alla base dei dati, si potrà prevedere uno switch per ripristinare la situazione iniziale, magari durante un fermo di servizio programmato; l’urgenza di tale operazione è da valutare di volta in volta, in particolare a seconda del tipo di server presenti: se sono tutti equivalenti, non ci dovrebbero essere problemi nell’attesa, mentre diversa è la valutazione nel caso in cui, ad esempio, il vecchio master sia un quadriprocessore e gli slave solo dei semplici mono-processori.
Affidabilità e solo affidabilità
Si parlava di scalabilità, ma sono molti i casi in cui un database MySQL è più che sufficiente, e quello che si vuole ottenere è solo migliorare l’affidabilità per non rischiare di vedere il servizio cadere magari per un guasto hardware.
Un possibile scenario vede la presenza di due server database in modalità attiva/passiva o attiva/attiva, con uno o due IP virtuali utilizzati per accettare le connessioni e che, in caso di caduta di uno dei nodi, vengono migrati secondo necessità.

Lo schema di figura 5 è il più semplice: i due nodi hanno un indirizzo privato per la gestione degli stessi (di solito posizionati su una rete di management separata, quando possibile), un indirizzo privato per la replicazione e dispongono di un indirizzo virtuale al quale arrivano le connessioni dal layer applicativo (siano essi Apache o Application Server).
L’IP virtuale viene assegnato, in partenza, a uno soltanto dei due server.
Tra i due nodi è attiva una replicazione che, per la particolarità della configurazione, viene detta circolare: in breve, ogni nodo è, contemporaneamente, master e slave dell’altro e ogni scrittura effettuata sul server .110 viene propagato sul server .120 e viceversa.
La configurazione è analoga a quelle già viste, anche se in modalità “incrociata”:
# Nodo 1 - IP reale 172.16.2.110
master-host = 172.16.2.120
master-user = nodo01
master-password = pass01
# Nodo 2 - IP reale 172.16.2.120
master-host = 172.16.2.110
master-user = nodo02
master-password = pass02
La direttiva log-bin deve essere abilitata su entrambi i server.
Si riavviano i due nodi per far leggere la nuova configurazione: eventualmente ci sarà da impartire reset master e reset slave, a seconda dei dati presenti nei file di log degli stessi. La situazione, alla fine, sarà simile alla seguente:
mysql-110> show slave status \G
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.2.120
Master_User: nodo01
Master_Log_File: mysql-bin.000001
Mysql-120> show slave status \G
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.2.110
Master_User: nodo02
Master_Log_File: mysql-bin.000001
Tutto sta replicando correttamente. Creiamo sul primo nodo un database di test:
mysql-110> create database test_ha;
Nel secondo creiamo una tabella:
mysql-120> use test_ha;
mysql-120> create table tab_ha (
id int auto_increment primary key, testo text);
Tutto sembra funzionare perfettamente. Se proviamo ad inserire alcuni record
mysql-110> insert into tab_ha values (
NULL, "primo record?");
mysql-120> insert into tab_ha values (
NULL, "secondo record?");
vengono entrambi replicate senza problemi. Ma cosa succederebbe se le scritture venissero effettuate contemporaneamente? Un modo veloce per effettuare una simulazione di un accesso concorrente alla base dati, considerando la velocità intrinseca del meccanismo di replicazione, consiste nel bloccare la replica in toto, e farla poi riprendere successivamente:
mysql-110> stop slave;
mysql-120> stop slave;
Inseriamo sia sul primo server che sul secondo un record:
mysql-110> insert into tab_ha values (
NULL, "terzo record?");
mysql-120> insert into tab_ha values (
NULL, "terzo record?");
Gli auto_increment dei due server hanno attribuito lo stesso ID progressivo:
mysql-110> select id, testo, @@server_id
from tab_ha where id=3;
| id | testo | @@server_id |
| 3 | terzo record? | 110 |
mysql-120> select id, testo, @@server_id
from tab_ha where id=3;
| id | testo | @@server_id |
| 3 | terzo record? | 120 |
Facendo ripartire la replicazione, il risultato non può che essere disastroso.
mysql-110> slave start;
mysql-110> show slave status \G
Slave_IO_Running : Yes
Slave_SQL_Running : No
Last_Errno : 1062
Last_Error : Error 'Duplicate entry '3' for
key 1' on query. Default database: 'test_ha'.
Query: 'insert into tab_ha values (NULL, "terzo record?")'
Risultato analogo per l’altro nodo. Ecco quindi che l’HA gestita con due serve attivi può dare sì benefici (due server che bilanciano le connessioni anche in scrittura), ma anche qualche piccolo problema al contorno, risolvibile solo se ben gestito.
La soluzione a questa empasse può avvenire in due modi: il primo, più semplice, è di non permettere di utilizzare i due server attivi contemporaneamente, ma solo uno alla volta (approccio attivo/passivo). Ecco che l’utilizzo di un solo IP virtuale aiuta nella configurazione, in quanto i client possono connettersi solo a quell’IP, e quell’IP risulta assegnato solo su uno dei server gestito da meccanismi di heartbeat.
Nel caso, invece, che si vogliano utilizzare i due server contemporaneamente, è opportuno utilizzare le direttive auto_increment_increment e auto_increment_offset, che permettono di impedire un conflitto di ID: il primo valore indica di quanto aumentare per ogni inserimento il valore del campo id, il secondo indica il valore di partenza dell’auto_increment stesso (che comunque deve essere inferiore o uguale al valore di auto_increment_increment)
mysql-110> show variables like "auto_increment%";
| Variable_name | Value |
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
E’ ovvio che, in caso di due server, inserire come valore di partenza 1 e 2, rispettivamente per il primo e secondo server, con un incremento di 2 ad ogni insert, si ottiene che il primo server utilizzi sempre i valori ID dispari, e il secondo server tutti gli ID pari, impedendo qualsivoglia conflitto.
mysql-110> set auto_increment_increment=2;
mysql-110> insert into tab_ha values (
NULL, "che id avrà?");
mysql-110> insert into tab_ha values (
NULL, "che id avrà?");
mysql-110> select * from tab_ha;
[...]
| 3 | terzo record? |
| 5 | che id avrà? |
| 7 | che id avrà? |
Questa soluzione, estremamente semplice, impedisce i problemi visti sopra, ma farà storcere il naso a chi utilizza i campi auto_increment come progressivo di inserimento (un ordinamento su id, nell’esempio, non garantirà più l’ordinamento temporale dei record, sarà necessario utilizzare i timestamp, meglio se valorizzati dai trigger di MySQL 5.0) e chi li utilizza come ID seriale per svariati compiti (no, non vanno usati per fatture o ricevute o altri documenti fiscali!), dovrà optare per qualcosa di diverso.
Il caso presentato è estremamente semplice, ma ci sono altri scenari, più complessi da analizzare, che potrebbero portare a situazioni analoghe, e che meritano uno studio approfondito.
Nel caso uno dei due nodi abbia una failure, l’altro continuerà ad essere operativo: al rientro del server caduto, esso si dovrà agganciare alla replicazione e aggiornerà la propria base di dati: è ovvio che, fino a quando il server non si sarà perfettamente allineato, è opportuno evitare che venga interrogato, perché quasi certamente fornirebbe informazioni non corrette e/o aggiornate.
L’utilizzo dell’IP virtuale può risolvere, almeno in parte, molti dei problemi visti sopra, perché inserisce una sorta di “semaforo” alla connessione, rendendola di fatto esclusiva verso un solo server (anche se molto dell’affidabilità dipende dalle tecniche con la quale la si implementa).
Conclusioni
Una soluzione scalabile e affidabile è fondamentale per chi non vuole avere limiti di crescita nel proprio business: a volte si è costretti a sperare di non avere troppo successo perché, altrimenti, le richieste sarebbero così tante da non poter essere servite. MySQL offre tecnologie estremamente semplici da gestire, affidabili e ad un costo più che accettabile, zero!
Nelle prossime puntate, se i lettori saranno interessati, si potrà osservare da vicino il nuovo motore NDB e le nuove soluzioni di bilanciamento e high availability basate su MySQL Cluster “five nine” 99.999%.
Riquadro 1: Commit a due fasi
Nonostante la replicazione sia estremamente veloce, la possibilità che, in caso di caduta del master, qualche record non venga inoltrato agli slave esiste, è poco probabile, ma è reale. La replicazione nativa, come più volte spiegato, è asincrona, e in particolare non implementa in alcun modo la cosiddetta two-phase-commit: se una transazione utilizza questa tecnica, essa dà esito positivo solo quando i due nodi (in genere, almeno due, poi possono essere in numero maggiore) effettuano l’operazione con successo garantendo così che, in caso di caduta del server, almeno l’altro server abbia eseguito quell’operazione con successo.
Quando il valore attribuito alla perdita di un record è estremamente elevato (ad esempio, una transazione bancaria) può essere conveniente utilizzare una soluzione HA più sicura e estremamente più costosa, come uno storage condiviso tra i nodi… oppure utilizzare il MySQL Cluster 99.999%, che implementa la two-phase-commit nativamente.