Di Corrado Pandiani, pubblicato su Linux&C. n° 64.
Le novità più interessanti della versione 5.1 di MySQL
Con il rilascio della versione 5.0 MySQL ha introdotto le funzionalità avanzate che da tempo tanti utilizzatori chiedevano: stored procedure, stored function, view e trigger tanto per citare le principali. Possiamo quindi pensare alla 5.0 come alla versione che ha consentito a MySQL di fare un importante salto di qualità, aprendosi la strada verso un utilizzo più maturo anche al di fuori dell’ambito del web dove aveva trovato storicamente grande slancio.
Il rilascio della 5.1 stabile, che dovrebbe essere imminente (nel momento in cui scriviamo è disponibile la 5.1.23rc – Release Candidate, il prossimo passo dovrebbe essere la GA – Generally Available), introduce nuove funzionalità, pensate principalmente per il datawarehousing e che dovrebbe consentire un ulteriore balzo in avanti verso nuovi mercati.
MySQL 5.1 offre come novità di spicco una funzionalità che consente la gestione di tabelle di grandi dimensioni in maniera trasparente ed efficiente: il partitioning. E’ considerata la funzionalità più caratterizzante di questa versione, anche se ci sarebbe da citarne di altrettanto interessanti: l’event scheduler, i log tabellari, la replicazione row-based, l’interfaccia plugin, la replicazione e le tabelle su disco per MySQL Cluster, le funzioni XML.
In cosa consiste il partizionamento
Il partizionamento è una tecnica di progettazione fisica delle tabelle non certo nuova e con la quale molti DBA avranno già familiarità. Il principale motivo per cui ad un certo punto si decide di operare il partizionamento di una tabella, cioè di spezzarla in tabelle più piccole, è di ridurre la quantità di dati letta dalle query SQL al fine di ottenere tempi di risposta migliori.
Il partizionamento viene fatto in base ad una certa logica ben definita. Facciamo un esempio: supponiamo di avere la tabella con tutto l’elenco telefonico della Repubblica Popolare Cinese, parliamo grossomodo di almeno un miliardo di record e, supponendo che ogni record contenga i campi nome, cognome, indirizzo, città, provincia e numero di telefono per un totale di circa 80 byte a riga, il conto è presto fatto, siamo di fronte ad una tabella di 80GB circa.
Apriamo a questo punto una piccola parentesi sulla questione delle dimensioni e su cosa possa essere considerato effettivamente grande e cosa invece no; ci preme ricordare che non esiste un metro universale di giudizio, la valutazione da farsi è sempre relativa alla realtà che stiamo formalizzando ed è fortemente influenzata da fattori hardware e software. Insomma, ciò che a noi può sembrare enorme, calato nella nostra realtà, potrebbe non esserlo in altre: tutto è relativo!
Chiarito ciò, asseriamo che nel nostro caso qualche decina di GB per una sola tabella sono effettivamente tanti. Decidiamo quindi di suddividerla in sottotabelle più piccole per ottimizzare le interrogazioni.
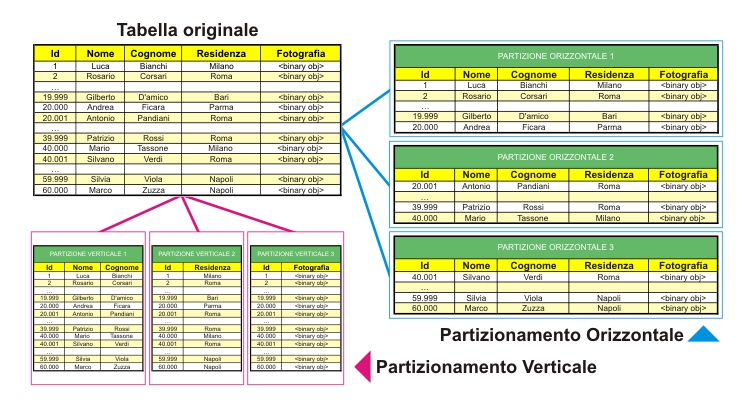
 Esistono due tecniche per partizionare una tabella: col partizionamento orizzontale si creano tante tabelle identiche a quella di partenza (con nomi ovviamente diversi) e si ridistribuiscono i record originali tra di esse. La cosa fondamentale è decidere la logica di distribuzione dei record, quella che più appropriatamente chiamiamo la funzione di partizionamento. Nel nostro caso potremmo ad esempio utilizzare l’ordinamento alfabetico creando una tabella per ogni iniziale del campo cognome e inserire i record in ognuna di esse in maniera appropriata. Facile intuire come ad esempio la ricerca di un certo cognome risulti ora più efficiente; il server deve aprire e fare la ricerca su una tabella di dimensioni decisamente più contenute rispetto a quella di partenza. Oppure potremmo scegliere di creare tante tabelle quante sono le province cinesi e di distribuirvi all’interno i vari record in base alla residenza anagrafica. In questo secondo caso una query che dovesse elaborare delle statistiche di qualche tipo su una singola provincia o distretto telefonico trarrebbe beneficio da questa nuova struttura. Ad essere usata sarebbe una sola tabella con un numero decisamente inferiore di record.
Esistono due tecniche per partizionare una tabella: col partizionamento orizzontale si creano tante tabelle identiche a quella di partenza (con nomi ovviamente diversi) e si ridistribuiscono i record originali tra di esse. La cosa fondamentale è decidere la logica di distribuzione dei record, quella che più appropriatamente chiamiamo la funzione di partizionamento. Nel nostro caso potremmo ad esempio utilizzare l’ordinamento alfabetico creando una tabella per ogni iniziale del campo cognome e inserire i record in ognuna di esse in maniera appropriata. Facile intuire come ad esempio la ricerca di un certo cognome risulti ora più efficiente; il server deve aprire e fare la ricerca su una tabella di dimensioni decisamente più contenute rispetto a quella di partenza. Oppure potremmo scegliere di creare tante tabelle quante sono le province cinesi e di distribuirvi all’interno i vari record in base alla residenza anagrafica. In questo secondo caso una query che dovesse elaborare delle statistiche di qualche tipo su una singola provincia o distretto telefonico trarrebbe beneficio da questa nuova struttura. Ad essere usata sarebbe una sola tabella con un numero decisamente inferiore di record.
Col partizionamento verticale si creano più tabelle con lo stesso numero di record della tabella di origine, ma ridistribuendo le colonne. Nel nostro caso potremmo creare una tabella con le sole colonne nome e cognome e un’altra con i rimanenti campi. Ha poco senso, lo ammettiamo, ed in effetti nella realtà questa tecnica è la meno usata anche perché implica di norma la duplicazione dell’intera chiave primaria in ogni sottotabella. Questa tecnica è valida, tuttavia, quando la tabella di partenza è costituita da molte colonne, la maggior parte delle quali usate di rado nelle ricerche. In tal caso separare le poche colonne usate più frequentemente dalle tante usate di rado porta a qualche significativo beneficio in termini di performance.
Un altro ambito di applicazione è quando si separano le colonne a dimensione variabile (varchar, varbinary, text, blob), di norma più lente, da quelle a dimensione fissa (tutti gli altri tipi), più veloci.
Lo scotto da pagare quando spezziamo le tabelle senza un opportuno supporto da parte del motore del database è che dovremo creare una serie di tabelle separate e l’applicazione che fa uso del DB deve essere messa a conoscenza della logica che si è utilizzata, in modo da decidere di volta in volta su quali sottotabelle operare. Si tratta di uno sforzo computazionale in più e soprattutto la manutenibilità del software risulta più difficile nel momento in cui dovessimo decidere di partizionare le tabelle in un modo diverso da quello deciso inizialmente; dovremmo non solo ridistribuire nuovamente i record, ma riscrivere anche parte della applicazione per renderla edotta della nuova logica.
Per chi ha già esperienza di MySQL e sta subito pensando alle tabelle MERGE, diciamo subito che la questione è ben diversa, anche se non è questo il momento di affrontare l’argomento.
Il partitioning di MySQL 5.1
MySQL 5.1 consente di partizionare una tabella automaticamente una tabella, facendo gestire le sotto tabelle direttamente al motore database. Al momento è supportato solo il partizionamento orizzontale.
La definizione del tipo di partizionamento, della funzione di partizione, del numero di partizioni e della loro posizione sul filesystem è definibile semplicemente con il comando CREATE TABLE.
Una volta creata la tabella e definito il partitioning nelle sue parti essenziali, la gestione della ripartizione dei record tra le varie partizioni avviene in maniera totalmente trasparente ed automatica. La logica di ripartizione dei record, ivi incluso lo spostamento degli stessi da una partizione ad un’altra in caso di modifica del valore di certi campi, è gestita dal server.
In pratica quello che in passato doveva necessariamente essere implementato a livello applicativo, viene ora gestito internamente dal DBMS in maniera molto efficiente.
La visione esterna di una tabella partizionata non è dissimile da quella di ogni altra tabella; le applicazioni ed i client che si collegano al DB hanno la sensazione di operare su una sola grande tabella, ignorando ogni dettaglio sottostante in merito al partizionamento, mentre invece il motore del database opera su tabelle più piccole, con i vantaggi di cui abbiamo parlato.
Ci sono poi altri vantaggi di importanza decisamente non secondaria: il partitioning consente ad esempio di superare il limite sulla dimensione dei file di certi filesystem, consentendo di avere tabelle grandi a piacere aumentando il numero delle partizioni. Inoltre, il fatto di poter creare ogni partizione in un punto qualsiasi del filesystem consente di aumentare considerevolmente le perfomance in quelle architetture in cui si possono sfruttare accessi paralleli su dischi diversi.
La gestione dei dati risulta inoltre facilitata; creando in maniera intelligente le partizioni, si possono effettuare operazioni che normalmente sarebbero molto onerose, sfruttano le sole partizioni necessarie senza coinvolgere tutte le altre. Ad esempio, in una ipotetica tabella degli ordini evasi da un negozio, partizionata in base all’anno di registrazione, risulta molto semplice cancellare tutti i record di una certa annata, basta rimuovere la partizione relativa con un apposito comando anziché eseguire un DELETE sull’intera tabella.
La rimozione di una partizione si traduce in pratica nella semplice cancellazione di un file su disco.
Il partitioning si può definire per tabelle MyISAM, InnoDB, Archive e NDB, ma non per gli altri tipi di engine. In particolare c’è da segnalare come il partitioning (in questo caso implicito) sia la tecnica utilizzata da MySQL Cluster per la ripartizione delle tabelle all’interno dei nodi dati, caratteristica che, insieme ad altre, lo rende una soluzione molto performante.
I paradigmi di partizionamento disponibili in MySQL 5.1 sono quattro: by range, by list, by hash, by key.
Prima di procedere con i dettagli per ognuno dei tipi, facciamo qualche premessa. Anzitutto gli esempi che seguiranno faranno sempre riferimento a tabelle di tipo MyISAM, ma si tenga presente che i comandi che utilizzeremo sono validi anche per gli altri engine supportati.
Partitioning by range
Nel partitioning by range le righe vengono assegnate alle varie partizioni in base al fatto che il valore di una certa colonna o della funzione di partizionamento cada all’interno di un certo intervallo.
Vediamo come creare una tabella in tal senso:
mysql> CREATE TABLE impiegato(
-> id INT UNSIGNED NOT NULL,
-> nome VARCHAR(50) NOT NULL,
-> cognome VARCHAR(50) NOT NULL,
-> data_assunzione DATE NOT NULL DEFAULT '1970-01-01',
-> data_licenziamento DATE DEFAULT '9999-12-31',
-> codice_reparto INT UNSIGNED NOT NULL)
-> PARTITION BY RANGE(YEAR(data_assunzione)) (
-> PARTITION p0 VALUES LESS THAN (2000),
-> PARTITION p1 VALUES LESS THAN (2002),
-> PARTITION p2 VALUES LESS THAN (2004),
-> PARTITION p3 VALUES LESS THAN (2006),
-> PARTITION p4 VALUES LESS THAN MAXVALUE
-> );
Prendiamo in esame la parte in grassetto; anzitutto diciamo a MySQL quale deve essere il tipo di partizionamento e quale colonna utilizzare per ripartire i record:
PARTITION BY RANGE(YEAR(data_assunzione))
in base al valore della funzione YEAR(data_assunzione) ogni record sarà posizionato in una delle partizioni che vengono definite in seguito.
Ogni partizione è identificata da un nome univoco arbitrario (p0, p1, ecc.) e, per ognuna di esse, dobbiamo definire il range di valori corrispondente. La definizione dei valori limite dei range devono essere necessariamente inseriti in maniera sequenziale dal minore al maggiore; in caso contrario l’operazione terminerà con un errore.
E’ buona cosa prevedere sempre come ultima partizione (p4 nel nostro caso) quella definita con la clausola VALUES LESS THAN MAXVALUE in modo tale che tutti i record che non dovessero cadere negli intervalli definiti in precedenza finiscano in quest’ultima. Senza l’ultima partizione definita in questo modo ogni record al di fuori dei range presenti genererebbe un errore di inserimento.
Andiamo a curiosare ora sul filesystem nella directory dei dati (in caso di incertezza utilizzate il comando SHOW VARIABLES LIKE ‘datadir’), troveremo i seguenti file:
# cd /usr/local/mysql/data/test
# ls -l impiegati*
-rw-rw---- [...] 8782 [...] impiegati.frm
-rw-rw---- [...] 40 [...] impiegati.par
-rw-rw---- [...] 0 [...] impiegati#P#p0.MYD
-rw-rw---- [...] 1024 [...] impiegati#P#p0.MYI
-rw-rw---- [...] 0 [...] impiegati#P#p1.MYD
-rw-rw---- [...] 1024 [...] impiegati#P#p1.MYI
[...]
Rispetto alle tabelle MyISAM tradizionali, costituite da soli tre file (frm: definizione e charset, MYD: dati, MYI: indici), ora abbiamo un nuovo file .par che definisce le partizioni e una coppia di file dati (MYD) e file indici (MYI) per ognuna delle partizioni definite, quindi in realtà l’operazione di partizionamento non riguarda solo i dati, ma anche gli eventuali indici presenti.
Nel caso in cui avessimo creato la tabella di tipo InnoDB, però, non avremmo trovato sul filesystem tali file. Nel caso di InnoDB, infatti, il partizionamento è gestito internamente al tablespace (lo spazio condiviso, di solito un unico grande file, nel quale sono memorizzate insieme tutte le tabelle InnoDB presenti nel DBMS e tutti i relativi indici).
Proviamo a fare qualche INSERT:
mysql> INSERT INTO impiegati
-> VALUES(1,'Giuseppe','Verdi','1995-05-05',null,5);
mysql> INSERT INTO impiegati
-> VALUES(2,'Mario','Rossi','2007-10-11',null,5);
mysql> INSERT INTO impiegati
-> VALUES(3,'Luigi','Bianchi','2004-10-11',
-> '2008-01-01',4);
Andiamo ora a verificare sul filesystem se i record sono stati inseriti nelle partizioni previste; basta vedere quali siano i file dati che sono aumentati di dimensione.
# ls -l impiegati*
-rw-rw---- [...] 32 [...] impiegati#P#p0.MYD
-rw-rw---- [...] 28 [...] impiegati#P#p3.MYD
-rw-rw---- [...] 36 [...] impiegati#P#p4.MYD
Le righe sopra riportate indicano le partizioni che sono variate. Il primo record è stato inserito in p0 in quanto l’anno 1995 è minore del primo valore di range definito: 2000. Il secondo record è stato inserito in p4 in quanto il valore 2007 è più grande di 2006 o, meglio, è minore di MAXVALUE. Il terzo record, il cui valore è 2004, è stato inserito in p3 essendo minore di 2006.
Facciamo notare infine che la funzione (o la colonna) di partizionamento deve restituire un valore intero.
Partitioning by list
Questo tipo di partizionamento è simile al precedente con la sola differenza che in questo caso anziché definire degli intervalli, vengono definite liste discrete di valori. Vediamo un esempio in cui creiamo le partizioni in base al valore del campo codice_reparto:
mysql> CREATE TABLE impiegati (
-> id INT UNSIGNED NOT NULL,
-> nome VARCHAR(50) NOT NULL,
-> cognome VARCHAR(50) NOT NULL,
-> data_assunzione DATE NOT NULL DEFAULT '1970-01-01',
-> data_licenziamento DATE DEFAULT '9999-12-31',
-> codice_reparto INT UNSIGNED)
-> PARTITION BY LIST(codice_reparto) (
-> PARTITION RNord VALUES IN (2,6,10,11),
-> PARTITION RSud VALUES IN (3,4,9,12),
-> PARTITION REst VALUES IN (1,5),
-> PARTITION ROvest VALUES IN (7,8,13)
-> );
In questo tipo di partizionamento non è possibile creare una partizione in cui inserire eventuali valori non previsti come nel caso del partition by range. Valori non validi restituiscono un errore di inserimento.
mysql> INSERT INTO impiegati
-> VALUES(1,'Giuseppe','Verdi','1995-05-05',null,5);
mysql> INSERT INTO impiegati
-> VALUES(2,'Mario','Rossi','1995-05-05',null,10);
mysql> INSERT INTO impiegati
-> VALUES(3,'Carlo','Bianchi','2005-12-05',null,15);
ERROR 1523 (HY000): Table has no partition
for value 15
Tutte le altre considerazioni sono le stesse viste in precedenza.
Partitioning by hash
Con i partizionamenti by range e by list, dove siamo noi a predeterminare la funzione di partizionamento, a lungo andare possiamo correre il rischio di ottenere partizioni molto diverse: alcune con molti ed altre con pochissimi record. Questa situazione porta ovviamente ad una disomogeneità dei tempi di risposta. Se non vogliamo correre questo rischio o non vogliamo scervellarci troppo a scegliere la funzione di partizionamento più appropriata, possiamo affidarci a MySQL e far
gestire tutto a lui in maniera automatica con il partitioning by hash. Con questo tipo di partizionamento il server distribuisce i record in maniera omogenea e consente di ottenere partizioni più o meno della stessa dimensione. Bisogna solo decidere quale sia la colonna (o anche in questo caso la funzione) in base alla quale partizionare e stabilire il numero di partizioni desiderate. Ad esempio:
mysql> CREATE TABLE part_hash
-> (col1 INT, col2 DATE, col3 CHAR(10))
-> PARTITION BY HASH ( YEAR(col2) )
-> PARTITIONS 5;
Valgono anche in questo caso le considerazioni precedenti ad eccezione del fatto che in questo caso il nome delle partizioni è gestito in automatico da MySQL. Resta valido il fatto che la funzione di partizionamento deve restituire un valore intero.
Partitioning by key
Il partitioning by key è simile a quello by hash ad eccezione del fatto che, mentre prima era necessario definire una funzione di partizionamento, in questo caso è MySQL a scegliere la funzione di hashing da utilizzare.
Possiamo specificare una colonna di partizionamento da utilizzare, altrimenti verrà utilizzata di default la PRIMARY KEY della tabella, oppure una colonna definita come UNIQUE.
Nel seguente esempio viene utilizzata la colonna col1 associata alla chiave primaria:
mysql> CREATE TABLE p_key1
-> (col1 INT, col2 INT, PRIMARY KEY(col1))
-> PARTITION BY KEY()
-> PARTITIONS 3;
mentre nel seguente viene utilizzata la colonna col2 associata alla UNIQUE KEY:
mysql> CREATE TABLE p_key2
-> (col1 INT, col2 INT, UNIQUE KEY(col2))
-> PARTITION BY KEY()
-> PARTITIONS 3;
Specificando invece una o più colonne bisogna tenere presente che devono essere sempre in parte comprese nella chiave primaria o devono coincidere con la chiave primaria stessa.
Vediamo un esempio in cui questa regola è violata ed otteniamo un errore:
mysql> CREATE TABLE p_err
-> (id INT, col1 INT, PRIMARY KEY(id))
-> PARTITION BY KEY(col1)
-> PARTITIONS 5;
ERROR 1503 (HY000): A PRIMARY KEY must include
all columns in the table's partitioning function
Questa è una importante differenza rispetto alle altre tipologie di partizionamento dove invece si può tranquillamente specificare colonne non necessariamente facenti parte della chiave primaria. Un’altra differenza è che in questo caso le colonne specificate possono essere di qualsiasi tipo, mentre negli altri casi devono essere necessariamente di tipo intero.
mysql> CREATE TABLE reddito (
-> codice_fiscale CHAR(16) PRIMARY KEY,
-> reddito INT)
-> PARTITION BY KEY(codice_fiscale)
-> PARTITIONS 10;
Query OK, 0 rows affected (0.07 sec)
Gestione delle partizioni
Una volta creata una tabella partizionata, questa non dovrà rimanere così per sempre, è possibile variarne in ogni momento il numero e la tipologia delle partizioni a seconda delle proprie esigenze.
La modifica del partizionamento implica normalmente lo spostamento di buona parte dei record (a volte tutti) per soddisfare alle nuove condizioni; questa operazione è tanto più onerosa quanto più è grande la tabella e tanto più questi spostamenti sono numerosi. L’operazione di modifica delle partizioni deve generalmente essere di tipo straordinario, deve essere ben ponderata e soprattutto dettata da esigenze reali.
Vediamo alcuni dei comandi più utili.
Aggiunta di una partizione nel caso di un by range:
mysql> ALTER TABLE impiegato
-> ADD PARTITION (PARTITION p5
-> VALUES LESS THAN (2008));
attenzione, però: si può aggiungere una partizione solo se è l’ultima della lista, non posso cioè aggiungere un nuovo intervallo che cada tra due già esistenti.
Aggiunta di una partizione nel caso di un by list:
mysql> ALTER TABLE impiegato
-> ADD PARTITION (PARTITION nuovoReparto
-> VALUES IN (14,15,16));
in questo caso l’istruzione non genera errori se nessuno dei valori indicati è presente in partizioni già esistenti.
La rimozione di una intera partizione è analoga per entrambi i casi, basta indicarne il nome:
mysql> ALTER TABLE impiegato DROP PARTITION p5;
la rimozione di una partizione implica anche la rimozione di tutti i record in essa contenuti.
Se vogliamo riorganizzare invece in modo diverso le partizioni presenti (ridistribuendo i record e senza perdere alcun dato) possiamo utilizzare il comando REORGANIZE.
Supponiamo di avere la seguente tabella così definita:
mysql> SHOW CREATE TABLE utenti\G
Table: utenti
Create Table: CREATE TABLE `utenti` (
`id` int(11) default NULL,
`nome` varchar(30) default NULL,
`cognome` varchar(30) default NULL,
`data_registrazione` date default NULL
) ENGINE=MyISAM DEFAULT CHARSET=latin1
PARTITION BY RANGE ( YEAR(data_registrazione) ) (
PARTITION p0 VALUES LESS THAN (2006) ENGINE = MyISAM,
PARTITION p1 VALUES LESS THAN (2007) ENGINE = MyISAM,
PARTITION p2 VALUES LESS THAN (2008) ENGINE = MyISAM,
PARTITION p3 VALUES LESS THAN (2009) ENGINE = MyISAM
)
possiamo ad esempio modificare la partizione p0, spezzandola in due:
mysql> ALTER TABLE utenti REORGANIZE PARTITION
-> p0 INTO ( PARTITION p01 VALUES LESS THAN (2005),
-> PARTITION p02 VALUES LESS THAN (2006));
Possiamo anche fare il merge di partizioni adiacenti:
mysql> ALTER TABLE utenti
-> REORGANIZE PARTITION p01,p02 INTO (
-> PARTITION p0 VALUES LESS THAN (2006));
tornando in questo modo alla tabella come era in origine oppure possiamo anche reimpostare tutte le partizioni, passando ad esempio dalle 4 originarie a 2 solamente:
mysql> ALTER TABLE utenti
-> REORGANIZE PARTITION p0,p1,p2,p3 INTO (
-> PARTITION m0 VALUES LESS THAN (2007),
-> PARTITION m1 VALUES LESS THAN (2009));
Per il partitioning by list, il comando REORGANIZE funziona allo stesso modo.
Per quanto riguarda i partizionamenti by hash e by key, le cose sono un po’ diverse ed inoltre non è possibile fare il DROP di una partizione come per gli altri casi. Possiamo, però, diminuire ed aumentare a piacere il numero delle partizioni e, come sempre, MySQL si occuperà automaticamente di ridistribuire opportunamente tutti i record.
Supponiamo di avere una tabella con 10 partizioni:
mysql> CREATE TABLE utenti (
-> id INT,
-> nome VARCHAR(30),
-> cognome VARCHAR(30),
-> data_registrazione DATE )
-> PARTITION BY HASH( MONTH(data_registrazione) )
-> PARTITIONS 10;
per ridurre ad esempio il numero della partizioni da 10 a 6 dobbiamo usare comando COALESCE indicando il numero di partizioni da eliminare:
mysql> ALTER TABLE utenti COALESCE PARTITION 4;
Ovviamente il numero indicato non può essere uguale o superiore al numero di partizioni presenti se non vogliamo ottenere un errore.
Infine, per aggiungere altre partizioni, utilizziamo:
mysql> ALTER TABLE utenti ADD PARTITION PARTITIONS 4;
Performance
Proviamo finalmente a fare qualche query e cerchiamo di capire cosa succede quando leggiamo i record da una tabella partizionata. Utilizzeremo il comando EXPLAIN (lo abbiamo spiegato in dettaglio nel numero 59 di Linux&C) che ci consente di sapere dal server un po’ di informazioni su come viene eseguita una query: quali indici saranno utilizzati, la stima di quante righe verrano lette, in che modo verrano risolti i join e altro ancora. Per lo scopo della nostra trattazione utilizzeremo una variante introdotta in MySQL 5.1 per avere qualche informazione in più in merito alle partizioni: EXPLAIN PARTITIONS. In questo modo il server ci dirà, oltre al resto, anche quali partizioni saranno utilizzate.
Quando si parla di performance è anche il caso di fare qualche misurazione, per dimostrare che i vantaggi promessi dalla teoria sono anche reali. Per fare, però, delle misurazioni attendibili ci serve una tabella di grandi dimensioni, non di svariati GB ma grande a sufficienza per apprezzare il tempo di esecuzione di una query. Nel riquadro 2 potete seguire passo passo l’esempio, riproducibile, in cui grazie ad una stored procedure costruiamo dapprima una tabella MyISAM non partizionata di 160MB di dati casuali. Assicuratevi di avere il doppio di tale spazio a disposizione sul vostro disco, dato che poi costruiremo l’analoga tabella partizionata in diversi modi e vedremo come variano i tempi di esecuzione di una stessa query: è abbastanza evidente che, usato nel modo corretto, il partitioning porta effettivamente a dei significativi vantaggi in termini di tempo di risposta.
Conclusioni
Il partitioning in MySQL 5.1, come abbiamo già avuto modo di dire, è probabilmente la più importante delle novità e consente di ottenere tempi di risposta, nell’ambito di tabelle di grande dimensione, di molto inferiori rispetto alle soluzioni possibili con le vecchie versioni.
Bisogna, però, stare attenti, un uso non corretto del partitioning non porta a nessun vantaggio, anzi, potrebbe anche peggiorare la situazione. Quindi, prima di iniziare ad utilizzare questa nuova ed interessante opportunità è necessario fare qualche prova (a partire magari dagli spunti offerti da questo articolo) e approfondire qualche dettaglio un po’ più spinoso facendo riferimento alla documentazione ufficiale.
Riquadro 1: Le altre novità di MySQL 5.1
Event scheduler: consente la creazione di eventi da eseguire ad intervalli regolari iniziando e finendo in determinati momenti. Ad un evento è associato del codice da eseguire, scritto con lo stesso linguaggio usato per descrivere stored procedure e trigger. In pratica, ciò che si può fare appoggiandosi al cron di sistema, è stato portato direttamente all’interno del DBMS.
Replicazione row-based: la replicazione finora funzionava inviando da una macchina master ad altre macchine slave le query di modifica dei dati. Ora è possibile replicare inviando dal master non solo gli statement SQL, ma anche i dati veri e propri in un formato binario. Questa nuova funzionalità risolve ad esempio certi problemi sorti in passato con la replicazione delle stored function. C’è anche la possibilità di gestire la replicazione in modo misto: invio agli slave sia le query SQL sia i valori dei record, il server sceglie il modo più opportuno a seconda del caso.
Plugin API: possibilità di caricare e disabilitare componenti aggiuntivi a runtime, senza riavviare il server. Al momento è una della novità ancora poco sviluppate, ma consente già di caricare un plugin apposito per il parsing full-text. Consentirà anche di abilitare e disabilitare a runtime storage engine di terze parti o autoprodotti, questa sarà sicuramente la cosa più interessante.
Log tabellari: c’è la possibilità di far scrivere alcuni dei file di log del server (lo slow_log e il general_log) in tabelle apposite del DBMS. In questo modo la consultazione di tali log diviene pià facile e flessibile visto che lo si può fare direttamente con interrogazioni SQL. Il monitoring del DB e il debugging delle applicazione risultano agevolati.
MySQL Cluster disk data: nelle vecchie versioni il Cluster teneva tutti i dati esclusivamente in memoria; questa caratteristica poteva divenire rapidamente limitante per il consumo eccessivo di RAM. La nuova versione invece consente di scrivere i dati delle tabelle anche su disco facendo così risparmiare la memoria. Il funzionamento non è dei più intuitivi al momento, ma è un bel passo avanti.
MySQL Cluster Replication: è possibile replicare un intero cluster su un altro cluster oppure su un altro DB anche se non è presente il cluster.
Funzioni XML: ci sono due nuove funzioni per leggere e manipolare abbastanza facilmente i campi nei quali sia stato inserito del codice XML. Le funzioni ExtractValue() e UpdateXML() sono state implementate con il pieno supporto di Xpath.
Riquadro 2: Le performance del partitioning
Scriviamo una stored procedure per creare due tabelle contenenti gli stessi dati casuali, una partizionata ed l’altra non partizionata.
mysql> DELIMITER //
mysql> CREATE PROCEDURE popola_tabella (IN numero_record INT)
-> BEGIN
-> DECLARE contatore INT DEFAULT 0;
-> DROP TABLE IF EXISTS utente_nopart;
-> DROP TABLE IF EXISTS utente_part;
-> CREATE TABLE utente_nopart(
-> id INT UNSIGNED,
-> nome VARCHAR(32) NOT NULL,
-> cognome VARCHAR(32) NOT NULL,
-> data_registrazione DATE NOT NULL);
-> CREATE TABLE utente_part(
-> id INT UNSIGNED,
-> nome VARCHAR(32) NOT NULL,
-> cognome VARCHAR(32) NOT NULL,
-> data_registrazione DATE NOT NULL)
-> PARTITION BY RANGE ( YEAR(data_registrazione) ) (
-> PARTITION p0 VALUES LESS THAN (2000),
-> PARTITION p1 VALUES LESS THAN (2001),
-> PARTITION p2 VALUES LESS THAN (2002),
-> PARTITION p3 VALUES LESS THAN (2003),
-> PARTITION p4 VALUES LESS THAN (2004),
-> PARTITION p5 VALUES LESS THAN (2005),
-> PARTITION p6 VALUES LESS THAN (2006),
-> PARTITION p7 VALUES LESS THAN (2007),
-> PARTITION p8 VALUES LESS THAN (MAXVALUE)
-> );
-> REPEAT
-> SET contatore=contatore+1;
-> INSERT INTO utente_nopart
-> VALUES(contatore, MD5(contatore), MD5(contatore),
MAKEDATE(ROUND(9*RAND()+1999),ROUND(365*RAND()+1)));
-> UNTIL contatore=numero_record
-> END REPEAT;
-> INSERT INTO utente_part SELECT * FROM utente_nopart;
-> END//
Query OK, 0 rows affected (0.00 sec)
mysql> DELIMITER ;
Lanciamo la stored procedure e creiamo le due tabelle con due milioni di record ciascuna (il tempo di esecuzione dipende dalla potenza del vostro computer, ma non sorprendetevi di aspettare qualche minuto).
mysql> CALL popola_tabella(2000000);
Query OK, 2000000 rows affected, 2 warnings (2 min 32.72 sec)
Eseguiamo una semplice query di conteggio sulla tabella non partizionata, ad esempio contiamo gli utenti registrati al nostro servizio dall’inizio del 2007 ad oggi:
mysql> SELECT COUNT(*) FROM utente_nopart
WHERE data_registrazione BETWEEN ‘2007-01-01’ AND CURDATE();
| COUNT(*) |
| 252035 |
eseguiamo la stessa query su quella partizionata:
mysql> SELECT COUNT(*) FROM utente_part
WHERE data_registrazione BETWEEN '2007-01-01' AND CURDATE();
| COUNT(*) |
| 252035 |
il tempo di esecuzione si è ridotto dell’80%, da 1.73 a 0.30 secondi, non male. Analizziamo le due query con EXPLAIN ed EXPLAIN PARTITIONS per vedere il perché. Iniziamo con quella \sualla tabella non partizionata:
mysql> EXPLAIN SELECT COUNT(*) FROM utente_nopart
WHERE data_registrazione BETWEEN '2007-01-01' AND CURDATE()\G
id: 1
select_type: SIMPLE
table: utente_nopart
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2000000
Extra: Using where
Come reso evidente da type: ALL viene fatto un full table scan, cioè viene letta l’intera tabella e vengono infatti analizzati due milioni di righe.
Analizziamo ora la query per la tabella partizionata:
mysql> EXPLAIN PARTITIONS SELECT COUNT(*) FROM utente_part
WHERE data_registrazione BETWEEN '2006-01-01' AND CURDATE()\G
id: 1
select_type: SIMPLE
[...]
table: utente_part
partitions: p8
type: ALL
rows: 333323
qui si vede invece che non vengono lette tutte le righe della tabella, ma solo quelle della partizione p8 per un totale di soli 333.323 record. Da questo motivo dipende la miglior performance. Eseguiamo ora la query seguente che non ha una condizione espressa sulla colonna usata per il partizionamento e vediamo in entrambe le tabelle il risultato:
mysql> SELECT COUNT(*) FROM utente_nopart
WHERE cognome BETWEEN 'a' AND 'b';
| COUNT(*) |
| 124431 |
1 row in set (1.35 sec)
mysql> SELECT COUNT(*) FROM utente_part
WHERE cognome BETWEEN 'a' AND 'b';
| COUNT(*) |
| 124431 |
1 row in set (1.41 sec)
I tempi sono simili, anzi, nel caso della tabella partizionata addirittura un po’ più alto.
Anche EXPLAIN PARTITIONS ci rende evidente che:
mysql> EXPLAIN PARTITIONS SELECT COUNT(*) FROM utente_part
WHERE cognome BETWEEN 'a' AND 'b'\G
id: 1
select_type: SIMPLE
table: utente_part
partitions: p0,p1,p2,p3,p4,p5,p6,p7,p8
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2000000
Extra: Using where
sono lette tutte le partizioni, l’equivalente del full table scan.