di Patrizio Tassone, pubblicato su Linux&C. n° 61.
MySQL Cluster 99.999%: affidabilità e performance prima di tutto
Quando i dati dell’azienda sono nelle mani di un database, quel database deve essere una roccia. A seconda del tipo di attività in cui quella società si trova ad operare si possono anche tollerare fermi di servizio per manutenzione, per aggiornamento, anche per eventuali failure di qualche tipo; ci sono però ambiti dove niente di tutto questo è neppure ipotizzabile, e dove serve l’affidabilità di una soluzione “five nine”: 99.999% di uptime, che significano qualcosa come poco più di 5 minuti di stop in un anno.
MySQL, parlo del database standard, è già un prodotto estremamente affidabile e, senza scomodare soluzioni iper-ingegnerizzate, con le opportune accortezze, con utilizzo della replicazione e di soluzione di clusterizzazione classiche, si raggiungono (e parlo per esperienza personale) livelli di uptime prossimi al 100%.
Ci sono ambiti, però, dove un approccio del genere può non bastare: sono gli stessi ambiti dove i limiti della replica nativa di MySQL viene amplificata, dove neppure le patch relative al semi-sync di un gigante come Google sono sufficienti a risolvere il problema, dove neppure la clusterizzazione standard – seppur raffinata – può dare una mano.
Serve un database dove tutti i nodi sono contemporaneamente attivi, indistinguibili tra loro, dove contattare l’uno o l’altro non fa differenza, dove non c’è tempo di propagazione delle modifiche come nella replica nativa, dove i nodi sono totalmente interconnessi, dove la caduta di un nodo risulta totalmente trasparente all’applicazione: poco importa se una soluzione di questo genere può avere – come è ovvio che sia – dei limiti, poco importa se, come disse uno dei massimi esperti MySQL scherzando – ma non troppo – “ogni riferimento ad un RDBMS è puramente casuale”.
Serve un database parallelo, e – possibilmente – serve non dover pagare licenze per decine di migliaia di euro a processore.
In definitiva, serve MySQL Cluster “five nine”, disponibile sotto GPL, ma anche sotto licenza proprietaria (proprio come MySQL classico).
Un database “in-memory”
Non troverete nessuna installazione di MySQL Cluster nelle top 10 dei database mondiali: http://link.oltrelinux.com/9932db
Il perché è molto semplice: questa versione di MySQL si appoggia interamente alla memoria dei sistemi che partecipano al cluster, rendendo di fatto impossibile il raggiungimento di dimensioni enormi della base di dati.
Ma questo, a pensarci bene, non è un problema. MySQL Cluster non è la soluzione per tutti i problemi, anzi, la scelta dovrebbe andare prima su altre soluzioni già note e stabili.
E’ bene ricordare – anche se dovrebbe essere scontato – che l’importanza di un database non è data dalla dimensione dello stesso. Pensate per un attimo all’autenticazione degli utenti in una rete VoIP, alla tracciabilità delle stesse telefonate, oppure alla localizzazione di un particolare numero di telefono nel sistema GSM, oppure ancora alla indicizzazione di parole chiave in un motore di ricerca: sono tutti ambiti dove un database raggiungerà a fatica qualche decina di GB, ciononostante un disservizio, ma anche solo un rallentamento nella risposta, potrebbe creare non propri problemi.
Sono tutti ambiti dove non ci sono query particolarmente complesse, dove spesso le interrogazioni non vanno oltre la ricerca a chiave, oppure la selezione dei record tra due valori per un determinato campo, oppure richieste di operazioni come somma o media: tutte operazioni, queste, facilmente parallelizzabili tra i vari nodi, e che permettono una risposta pressoché istantanea.
L’architettura del database
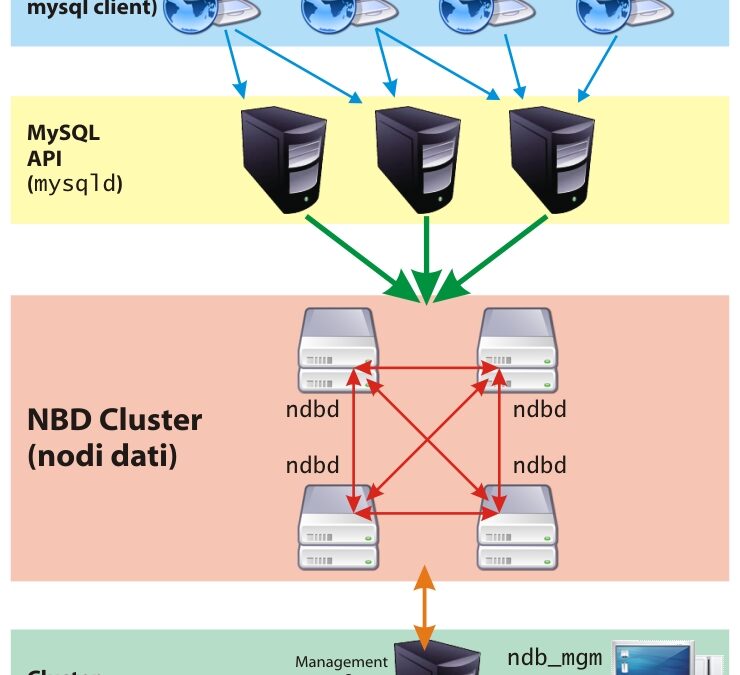
Per comprendere il funzionamento di MySQL Cluster è fondamentale dare uno sguardo alla architettura (figura 1) dello stesso, ai componenti e alle interazioni tra gli stessi.

La parola cluster fa intuire da subito che questa soluzione vede la presenza di più nodi: mentre il database classico può risiedere su un solo host, qua di host ne servono, per una prima configurazione, almeno quattro: due nodi storage, un nodo API (o SQL Node) e un nodo di management.
I nodi storage sono deputati esclusivamente della memorizzazione e alla interrogazione delle tuple. Leggono la configurazione dalla console di amministrazione (management console), e devono essere inizializzati alla prima esecuzione.
Il nodo SQL è il gateway che permette di effettuare le interrogazioni verso il sottosistema clusterizzato di memorizzazione delle informazioni: è costituito proprio dal classico MySQL che siamo abituati ad utilizzare, questo per permettere alle applicazioni di non essere modificate per beneficiare della soluzione di clustering.
Il nodo di management permette il controllo di tutto il sistema: provvede a consegnare ad ogni nodo la propria configurazione, permette l’esecuzione dei backup e dei restore, e tiene sotto controllo lo stato del sistema. Inoltre, in caso di failure dei nodi di storage, diventa l’arbitro (arbitrator) che decide quale sezione del cluster deve rimanere attiva (ruolo questo particolarmente critico in caso del cosiddetto split-brain) e quale invece deve effettuare uno shutdown per non compromettere l’integrità del database.
L’hardware che viene consigliato da MySQL AB è di fascia media: un sistema Linux o Unix, con due processori dual core, 16 GB di RAM per macchina (ma anche meno, dipende dalla dimensione del database), dei dischi veloci in raid 0+1 (quindi almeno 4 SCSI o SAS), Gigabit ethernet.
E’ di fondamentale importanza la velocità del network e l’affidabilità dello stesso: poiché i nodi sono totalmente interconnessi e scambiano messaggi di sincronia di continuo, la velocità della comunicazione tra i nodi rischia di diventare un collo di bottiglia. E’ così importante che, nel caso di utilizzo di più di 8 nodi, viene consigliata l’adozione di schede Dolphin, device a bassissima latenza molto utilizzati più nel campo del supercalcolo che nelle sale dati delle aziende.
E’ consigliabile, inoltre, che le schede di rete siano in channel bonding, e che i device ethernet (switch, schede di rete) siano anch’essi ridondati.
La scalabilità di questo genere di architetture è definita “scale-out”, che si contrappone all’altro approccio, lo “scale-up”: per aumentare la potenza di calcolo e lo spazio destinato alla memorizzazione dei dati è sufficiente aggiungere un nuovo server, anziché sostituire il vecchio sistema con uno più potente. Il costo dello scale-out è generalmente inferiore, e di un ordine di grandezza almeno, rispetto allo scale-up.
La memorizzazione distribuita delle informazioni: l’engine NDB
Per disporre dell’alta affidabilità richiesta, è fondamentale evitare qualsiasi single-point-of-failure e, per evitare i s-p-o-f, in un approccio share-nothing (senza cioè alcuno storage condiviso) è necessario duplicare l’informazione su altri nodi.
Per raggiungere un maggiore parallelismo l’informazione deve risiedere su più nodi possibile. Se si vuole massimizzare (potenzialmente almeno) il parallelismo, l’informazione deve risiedere su tutti i nodi.
Il nuovo storage NDBCluster applica queste due semplici regole meravigliosamente: scompone ogni tabella in “fette” (o slice), calcolando un hash particolare sulla chiave primaria, ed ogni slice viene memorizzato su un server diverso. Ogni slice ha un numero di repliche all’interno del cluster che può essere personalizzato, ma non può essere inferiore a 2 (sempre per non creare s-p-o-f). I nodi che dispongono della stessa slice fanno parte dello stesso node-group: fino a quando almeno un host all’interno del node-group è attivo, il cluster è funzionante anche se ha subito diversi failure.
In figura 2 possiamo vedere uno schema dello slicing.
Nello schema sono presenti quattro host fisici, e la tabella viene divisa in quattro slice: ogni slice viene replicato due volte, e per ogni replica esiste una copia “primaria” e una copia “di backup”.
Per la disposizione delle repliche, è evidente che Host 1 e Host 2 formino un node-group, in quanto – insieme – sono gli unici depositari della “fetta” F1 e F3.
Cosa potrebbe succedere in caso di crash dei sistemi o degli host? Qualche esempio chiarirà meglio il concetto:
- In caso di caduta di Host 1, il database non subirebbe alcun danno, in quanto le informazioni in possesso del server caduto sono replicati anche sul secondo host.
- In caso di caduta di Host 2, vale già quanto visto per Host 1.
- In caso di caduta di Host 1 e INSIEME di Host 3, il database non rileverebbe alcun problema, perché i server rimanenti possiedono, globalmente, l’intera informazione F1, F3 (su Host 2) e F2, F4 su Host 4.
- E’ altresì evidente che la caduta di un intero Node Group, cioè del Host 1 insieme a Host 2, oppure Host 3 insieme a Host 4, determinano lo shutdown del Cluster in quanto l’informazione è irrimediabilmente corrotta e sarà necessario provvedere al ripristino di un backup e al riavvio del sistema.
Come si può osservare dagli esempi fatti, MySQL Cluster va oltre la caduta del singolo server riuscendo, in alcune situazioni, a mantenere il servizio funzionante anche con la caduta di due nodi (che, su quattro sistemi, male non è di certo): tale sicurezza può essere aumentata incrementando il numero di repliche definite da file di configurazione.
Ovviamente, maggiore sarà la sicurezza minore sarà lo spazio a disposizione lasciato per i record (al pari di quanto avviene con i dischi in RAID).
Passiamo all’installazione
Dopo aver presentato a grandi linee le caratteristiche del database parallelo, è ora di iniziare a sperimentare un po’. Per il nostro esempio utilizzeremo una architettura composta da quattro server, un server di management (192.168.100.10), due server storage (192.168.100.20 e .30) e un nodo SQL (192.168.100.40), più che sufficiente per far apprezzare le novità del “five nine”.
L’esempio, puramente didattico, verrà eseguito in ambiente virtuale, e ogni singolo host avrà a disposizione “appena” 256 MB di memoria.
Sui nodi storage e sul nodo di interrogazione andrà installato MySQL, mentre sul nodo di management non sarà necessario provvedere all’installazione completa (noi faremo così per semplicità operativa): per l’esempio ho provveduto ad una installazione da file binari, nessun pacchetto quindi, in modo che sia più semplice seguire i pochi passaggi indipendentemente dalla distribuzione adottata, e nel riquadro 2 a pagina seguente trovate tutti i passaggi da effettuare.
Console di Management
La configurazione di tutti i parametri del cluster è centralizzata all’interno del nodo di management, dove è in esecuzione un apposito servizio: ogni nodo del cluster, sia esso storage o SQL, si connette a tale console e “richiede” la propria configurazione. All’interno della directory supports_files c’è un template di file di configurazione che possiamo utilizzare come prototipo, al pari di quanto avviene per MySQL.
# cp support-files/ndb-config-2-node.ini mysql-cluster.ini
Aprendo il file con un qualsiasi editor, si nota subito come siano presenti alcune sezioni con suffisso “default”, che specificano le impostazioni predefinite per quel particolare parametro: la sezione [ndbd default], quindi, stabilità i parametri generali per le varie sezioni [ndbd] che seguiranno poco più sotto, evitando inutili ripetizioni.
Tutte le tipologie di nodo trovano in questo file INI la sua configurazione: troviamo la sezione ndbd per i nodi che si occuperanno della memorizzazione dei dati, la sezione mysqld per gli host di interrogazione SQL, e nbd_mgmd per lo stesso nodo (ma possono essere più di uno, ridondati) di management.
Tra le voci presenti, analizziamo le più importanti:
- NoOfReplicas= 2 – indica quante repliche devono essere effettuate per ogni slice. Con due nodi, come nel nostro caso, non può essere che due il valore.
- DataMemory= 80M – indica lo spazio allocato per la memorizzazione dei dati veri e propri.
- IndexMemory= 24M – indica lo spazio allocato per la memorizzazione degli indici.
- DataDir= /var/lib/mysql-cluster – è la directory dove vengono memorizzati i file su disco, i vari check point, e dove eventualmente vengono memorizzati i backup del nodo. Nel nostro caso modificheremo questo parametro con /opt/mysql/data-cluster, non prima di aver creato tale directory e averla assegnata all’utente mysql (per coerenza con l’installazione di MySQL)
# mkdir /opt/mysql/data-cluster
# chown mysql /opt/mysql/data-cluster
E’ interessante notare come ogni singolo nodo disponga di un id, che viene indicato esplicitamente nel file di configurazione. Oltre all’id è possibile indicare l’indirizzo IP (o il nome dell’host) dal quale verrà effettuato il collegamento, per evitare che chiunque possa collegarsi al sistema.
Modifichiamo i parametri HostName con gli indirizzi IP specificati sopra, cancelliamo le occorrenze ulteriori delle sezioni [mysqld] e salviamo lasciando invariati tutti gli altri parametri.
Il file risultate è visibile nel riquadro 3.
Siamo pronti per lanciare in esecuzione – dall’utente mysql – il servizio relativo alla console di management (il numero davanti al prompt fa riferimento all’ultima cifra dell’IP del sistema):
(10)$ ndb_mgmd -f /opt/mysql/mysql-cluster.ini
(10)$ ps aux | grep ndb_mgmd
mysql 5331... ndb_mgmd -f mysql-cluster.ini
Colleghiamoci col client di console e lanciamo il comando show, che ci permette di avere una visione generale dello stato degli host coinvolti:
(10)$ ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm> show
Connected to Management Server at: localhost:1186
Cluster Configuration
[ndbd(NDB)] 2 node(s)
id=2 (not connected, accepting connect from 192.168.100.20)
id=3 (not connected, accepting connect from 192.168.100.30)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.100.10 (Version: 5.0.45)
[mysqld(API)] 1 node(s)
id=4 (not connected, accepting connect from 192.168.100.40)
Solo il nodo di management si è connesso al cluster (192.168.100.10, viene anche evidenziata la versione), e quest’ultimo è in attesa del collegamento degli altri host.
Attivazione dei nodi dati
L’installazione dei due nodi dati sarà identica: MySQL è già installato seguendo le istruzioni del riquadro e, come già visto per la management console, è stata creata la directory /opt/mysql/data-cluster. Vi è da specificare come contattare il server di management: l’indirizzo dello stesso dovrà essere inserito nel file my.cnf, non essendo utilizzati dal cluster meccanismi di auto-discovery di sorta. Aggiungete in fondo al file queste poche righe:
[mysqld]
ndbcluster
ndb-connectstring=192.168.100.10
[mysql_cluster]
ndb-connectstring=192.168.100.10
ndbd è il servizio di storage dei dati e, una volta lanciato, rimane attivo in background. La prima esecuzione deve essere invocata passando l’opzione –initial, in modo che possa preparare adeguatamente la directory indicata.
(20)$ ndbd --initial
(20)$ ls -la /opt/mysql/data-cluster/
drwxr-x--- 2 mysql mysql ... ndb_2_fs
-rw-r--r-- 1 mysql mysql... ndb_2_out.log
-rw-r--r-- 1 mysql mysql... ndb_2.pid
La console di management rileverà subito il nuovo arrivo:
(10)$ ndb_mgm -e show | grep Version
id=2 @192.168.100.20 (Version: 5.0.45, starting, Nodegroup: 0)
id=1 @192.168.100.10 (Version: 5.0.45)
Al nuovo nodo di storage è stato assegnato il Nodegroup 0. Dopo aver eseguito gli stessi comandi sull’altro nodo di storage, l’output della console cambia:
(10)$ ndb_mgm -e show | grep Version
id=2 @192.168.100.20 (Version: 5.0.45, Nodegroup: 0,
Master)
id=3 @192.168.100.30 (Version: 5.0.45, Nodegroup: 0)
id=1 @192.168.100.10 (Version: 5.0.45)
I due nodi deputati alla memorizzazione dei dati sono comparsi entrambi, e si sono auto-organizzati in un unico nodegroup; il primo che ha effettuato il collegamento è promosso a “master”, nodo primario per quel gruppo.
Attivazione del nodo SQL
All’appello manca ancora il server per effettuare le interrogazioni, abbastanza fondamentale visto che è anche l’unico sistema (per il momento almeno) per poter inserire qualcosa nel database e provare che funzioni.
Anche nel my.cnf del nodo SQL devono essere aggiunte le righe come già viste per i nodi storage. Inoltre è fondamentale verificare che l’engine NDB sia attivo, altrimenti addio alle funzionalità di clustering:
(40)$ mysql -e "show engines" | grep ndbcluster
ndbcluster DISABLED Clustered,
fault-tolerant, memory-based tables
Questo dovrebbe essere l’output prima dell’aggiunta delle righe al my.cnf: successivamente al posto di DISABLED troveremo YES. Sulla console intanto, appare anche l’id=4
(10)$ ndb_mgm -e show | grep id=4
id=4 @192.168.100.40 (Version: 5.0.45)
E’ stata dura, ma ce l’abbiamo fatta, e tutti i nodi del cluster sono riusciti a collegarsi alla console. Non rimane da fare altro che qualche prova: creiamo un database, poi una tabella, inseriamo qualche record e, successivamente, spegniamo uno dei due nodi dei dati.
(40)mysql> create database prova_ndb;
(40)mysql> use prova_ndb;
Database changed
(40)mysql> create table tab_ndb (id int auto_increment
primary key, testo char(100)) engine=ndbcluster;
(40)mysql> insert into tab_ndb (testo) values
("primo record con il cluster");
(40)mysql> insert into tab_ndb (testo) values
("secondo record con il cluster");
(40)mysql> select id, testo from tab_ndb;
| id | testo |
| 1 | primo record con il cluster |
| 2 | secondo record con il cluster |
A questo punto, spegniamo il nodo Master: uno shutdown pulito, uno spegnimento brutale, scegliete voi (magari uno snapshot della macchina virtuale, per non rischiare corruzioni di filesystem… in realtà basta un kill di ndbd).
Istantaneamente lo stato della console cambia:
(10)$ ndb_mgm -e show
[ndbd(NDB)] 2 node(s)
id=2 (not connected, accepting connect from 192.168.100.20)
id=3 @192.168.100.30 (Version: 5.0.45, Nodegroup: 0, Master)
Il secondo nodo è diventato Master, mentre il primo è disconnesso. E la query?
(40)mysql> select count(*) from tab_ndb;
| count(*) |
| 2 |
La caduta di uno dei due nodi dati non ha portato alcuna conseguenza e il database risponde senza alcun tipo di problema. Tutto secondo teoria.
Conclusione
MySQL Cluster ha un design veramente ben fatto, ma è necessario analizzare bene quando valga la pena di essere adottato e quando è meglio indirizzarsi verso altre tecnologie meno sperimentali.
Nella prossima puntata, se l’argomento sarà di interesse, potremo continuare ad approfondire la gestione del failover, il backup, e un esempio di migrazione da database MyISAM a NDBStorage.
Cercherò di limitare la dimensione delle macchine virtuali utilizzate in questo articolo, rendendole disponibili alla URL:
http://www.oltrelinux.com/risorse/LC61/mysql.tar.gz
Riquadro 1: Limitazioni di NDB
Non è tutt’oro quello che luccica, e pensare di migrare senza troppi problemi un database MyISAM o InnoDB su storage NDB per approfittare dell’affidabilità che questo offre è una illusione che svanirà presto non appena si passerà dalla lettura delle caratteristiche alla console :-).
E’ richiesta una profonda conoscenza, oltre che dell’ambiente MySQL Cluster, anche della vostra base di dati: già, perché lavorando in memoria ogni byte è sacro, e bisogna prima capire come viene utilizzata dal server, e poi centellinare la RAM laddove veramente serve.
Gli indici hanno un “costo elevato”, e devono essere utilizzati solo se veramente necessari. Tabelle senza chiavi primarie non devono esistere (questo, in generale, indipendentemente dal Cluster, dovrebbe essere una buona norma a prescindere) perché, in caso non sia specificata una primary key, viene auto-generata dal server con un hash che non aggiunge informazioni in più e consuma memoria.
Sono presenti le transazioni, ma solo nella modalità “REPEATABLE READ”, non quindi al livello elevato di InnoDB. Come MyISAM, non supporta le foreign key e, anche se sono permesse nella dichiarazione, sono semplicemente ignorate.
Non esistono i campi VAR: almeno fino alla versione 5.1, i campi variabili sono memorizzati con la massima occupazione di memoria: un varchar(255) sarà quindi un char(255).
Queste le principali limitazioni, ma ve ne sono anche altre che vi invito a consultare sul sito ufficiale di MySQL.
Riquadro 2: Installazione di MySQL da archivio binario (tar.gz)
Una volta effettuato il download da uno dei tanti mirror, ecco la sequenza classica delle operazioni per l’installazione:
# groupadd mysql
# adduser -g mysql mysql
# cd /opt
# tar xvfz /path/to/mysql-5.0.45-linux-i686.tar.gz
# chown -R root:mysql mysql-5.0.45-linux-i686
# ln -s mysql-5.0.45-linux-i686 mysql
# cd mysql
# scripts/mysql_install_db --user=mysql
# chown -R mysql data
Vista l’esiguità di memoria degli host, copiamo il file
my-small.cnf nella basedir di MySQL, insieme allo script mysql.server:
# cp support-files/my-small.cnf my.cnf
# cp support-files/mysql.server .
Modifichiamo il parametro basedir del file mysql.server per rispecchiare la path di installazione:
basedir = /opt/mysql
Aggiungiamo anche /opt/mysql/bin alla path di sistema, in modo che sia più semplice l’utilizzo dei comandi; inoltre effettuiamo un link simbolico per far apparire my.cnf in /etc:
# PATH=$PATH:/opt/mysql/bin
# ln -s /opt/mysql/my.cnf /etc/
Per far partire il server, sarà sufficiente il comando:
# /opt/mysql/mysql.server start
Riquadro 3: Il file mysql-cluster.ini
[ndbd default]
NoOfReplicas= 2
MaxNoOfConcurrentOperations= 10000
DataMemory= 80M
IndexMemory= 24M
TimeBetweenWatchDogCheck= 30000
DataDir= /opt/mysql/data-cluster
MaxNoOfOrderedIndexes= 512
[ndb_mgmd default]
DataDir= /opt/mysql/data-cluster
[ndb_mgmd]
Id=1
HostName= 192.168.100.10
[ndbd]
Id= 2
HostName= 192.168.100.20
[ndbd]
Id= 3
HostName= 192.168.100.30
[mysqld]
Id= 4
Hostname= 192.168.100.40
# choose an unused port number
# in this configuration 63132,
# 63133, and 63134 will be used
[tcp default]
PortNumber= 63132