da Gilberto Ficara | Set 10, 2009 | Articoli
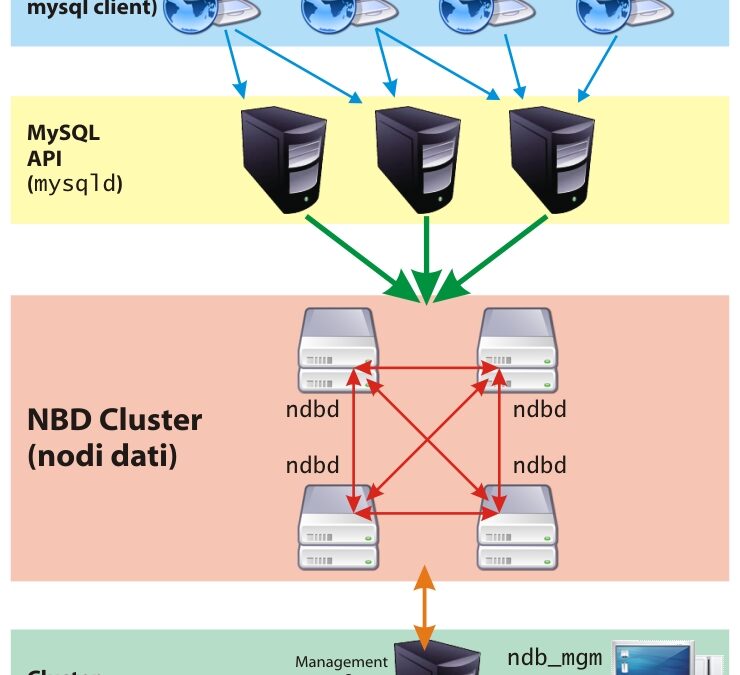
di Patrizio Tassone, pubblicato su Linux&C. n° 61. MySQL Cluster 99.999%: affidabilità e performance prima di tutto Quando i dati dell’azienda sono nelle mani di un database, quel database deve essere una roccia. A seconda del tipo di attività in cui quella...

da Gilberto Ficara | Gen 1, 2009 | Servizi
Il costo di un fermo di servizio è spesso molto elevato, mentre il costo dell’hardware piuttosto contenuto: rischiare l’interruzione dell’attività dell’azienda per un failure hardware è un rischio che può essere evitato facilmente: è...